Reflections on AGI and AITP 2024
My Ph.D. thesis was accepted Nov 29, 2023. This year I felt inspired by some prolific scholars whose published content is, imo, less rigorous than my blog posts. Perhaps my own standards are too high, and I could submit some of my work-in-progress ideas to the communities for feedback. Perhaps others can take on the baton or correct shortcomings, right? Research is a team pursuit.
I have some ideas on the phenomenological grounding of logical reasoning where reviewer commentary could be insightful, whether accepted for further discussions or not. My formal ethics ontology project could perhaps be interesting in some philosophy or ethics venue. So when the AGI-24 deadline approached, I noticed that they accepted 4-page position papers: do I have any reason not to submit a position I wish people would contemplate more? No! LFG~🔥. Likewise, for AITP-24, I didn’t wish to present on the ethics project again, simply showing more comprehensively refined versions of the same material, advertising the website version (now with plain English, not just SUMO ‘logic’). I had the idea to submit a presentation proposal: throughout my work on AI for theorem proving, I thought it’d be great if we held in mind the AGI-developing perspective. Thus, I could offer to give a presentation on how this view could guide theorem-proving research! Voila.
The experiment is a success! Writing the submissions is not much more involved than a blog post — if anything, they’re shorter and with restricted citation options. Presenting ideas on the importance of care and collaboration for beneficial AGI involved personally helpful distillation, too. Likewise, writing the extended abstract was an invitation to slightly more methodically chart out how the various AITP system components could map into cognitive architectures. The reviews were surprisingly positive, especially given how for AITP there was no backing research1To be fair, AITP is a cozy ‘conference’ with a focus on sharing research ideas and directions more than reporting successful, closed work.. One reviewer for AGI suggested rejecting the paper and provided references to exactly the kind of work I’d wished to see in the world: namely, people trying to work out a theory of delegating control over tasks (in the context of autonomous systems)2And as a bonus, Castelfranchi’s Theory of Tutelary Relationships was also proferred, which challenges the notion that it is sufficient to care for people as they wish, for in the case of children, we often believe we know better. Oh the paradoxes!. I’d actually have appreciated more reviewer feedback (assuming it’s of a high quality). I must say that receiving a venue with a curious, supportive audience to share my cherished philosophical and research-direction political views is humblingly grand~!
AGI-24 Submission Ideas
The submission to AGI, “Beneficial AGI: Care and Collaboration Are All You Need3The preprint on TechRxiv.“, became my first poster. I love this way of attending a conference: I upload a talk before the conference, show up with the poster, and I’m done! Now I can relax, enjoy the conference, and focus on the people and ideas. As to the content, I’d been wondering how to formulate the idea that it’s important to care for others by their own standards and that one of the best ways to do this is to empower them. A helpful insight is that most fears of “AGI doom” stem from hidden assumptions that the AGI is either not so intelligent or not so caring, moreover, where the AGI appears caring, it’s usually forcing its faulty understanding on us humans. I’d also become frustrated with some undercurrents in the “AI Safety” communities focusing on highly control-centric, totalitarian-leaning approaches, which, ironically, sometimes boil down to, “we need effectively caring AGIs, and this is why we need to perfect control over AGI value systems!” Of course, solving the “AI Control Problem” risks amplifying the “Human Control Problem“. So let’s cut to the chase and focus on caring AI!
To my pleasant surprise, there were other talks in this direction! For example, David Spivak, author of the book, Category Theory for the Sciences, which I enjoyed, gave a talk: “‘All My Relations’: Contributing to a Fabric of Belonging”. How do we mathematically express and work with care and delegation? We do computations for some reason, often for other beings, so it may help to develop the requisite mathematical framework. Exactly the kind of work I wished to see 🤓. I find it interesting how he agglomerated “care words” as essentially synonymous, i.e., if I define “care” in terms of “preferred states”, haven’t I only shifted over the burden of definition to “preference”?
David’s approach to focusing on “actualizing potential” is very interesting and, at a glance, somewhat vague. We AGI folke debated afterward: is lightning an actualization of potential? Does a ball on top of a hill care about rolling down, actualizing all this pent-up potential energy? Yet I agree with David and Levin’s broad view in “Care as the Driver of Intelligence” that it may help to find a framework that works on all levels of caring, cooperative organization. I’ve similarly wondered how “goals” might manifest as a physical phenomenon in dynamic systems: goals are sub-systems Gs of an autopoietic system S with a world model M for which the system tends to devote resources toward unifying Gs with sub-systems of M. Usually, the world model construction is grounded in perception in such a way that goal fulfillment cannot be done purely via the imagination. I, at least, have some deep resistance to violating this property in pursuit of my goals. Thus goals are conceptualized as pointers to potential that can be actualized in the world (model) — latent potentials in the world (model) represent potential goals.
Furthermore, Gaia’s ecosystem certainly seems to be autopoeitic4Self-organizing/creating. Perhaps we can abstract the core process beyond the limited scope of human-like enminded entities? One can say that there is a(n implicit) goal in a system when there is latent potential that the system exhibits a tendency toward actualizing? To care for some (implicit) goal is to devote resources toward its actualization (which could, arguably, involve simply maintaining awareness of the goal, which our neurotic narrative selves are great at!)5Arguably, “devoting resources toward” is yet another care word. Likewise, a “tendency to devote resources to X over Y”, is also a gloss for care..
Another special distinction worth noting is that between positive and negative goals. For example, stress reduction. I’ll posit that the healthy, homeostatic form my body maintains is an already actualized potential. Thus care involves devoting resources toward this sustenance, which can involve removing stressors (such as thorns). Negative goals are often actually protective in this view! The dichotomy would become: constructive and protective goals.
Can one conceive of a gravity well as an attractive, constructive goal in that cosmic resources are devoted toward expanding the center of mass? This would exemplify a goal without a separate form of the goal target distinct from the state of the world where the goal is realized. Gosh, the universe really cares for black holes! They’re so impressive — or is it the black holes themselves that care? And what of the starivores? Ok, ok, back to the topics at hand.
Why do we care for some goals/states and not others? This conceptualization doesn’t actually explain this, either. Some are simply preferred. In the case of embodied, enminded, enworlded entities such as humans, one could try to argue that our ongoing individuation is one natural goal. This fits in with ideas about framing growth in terms of transforming, protecting, or releasing systems of invariants. Transformative goals are those where there is potential for an invariant to form — is there some particular reason to choose one potential individuation to actualize over others? Subjectively, there certainly seem to be continuations of one’s cares that are more naturally compelling than others. Of course, as a member of the Universal Love Club, I find the goal of supporting all entities in the actualization of their potentials (dreams, desires, needs, fantasies, whatever — may ey experience life as ey see fit) to be rather natural. This runs into the obvious quagmires: clearly we care more for some subsystems of the cosmos (people) than others and perhaps should prioritize enriching and cherishing life over murderous drives, ya?
{kind=link}

Surely in the case of murderers and universal loving care, one could make an argument that siding with protecting life is a more effective, aligned choice than siding with the murderous intent (especially when the murderer has other concerns than murder). Yet I do not anticipate all potential conflicts of interest to logically resolve themselves. Perhaps there will be physics-like theories about how systems gravitate toward actualizing the greatest potentials? And we will only have to work with unexplained preferential concerns until we solve the maths? I think even without these answers, there’s a lot we can do in discussing care, indicators of care, delegation of tasks, empowering aid, etc.
David brought up another good point of agreement where value alignment is concerned: would a sufficiently caring, loving being with sufficient influence over its ongoing evolution choose to grow in such a way as to become uncaring? No. Consider the case of Phakyab Rinpoche who when being tortured in prison was concerned with losing compassion for his torturers. This isn’t about controlling the being’s values to lock them in place no matter what they are. I hypothesize that some values are more self-perpetuating and self-supporting than others. Is care for humans more likely to expand to care for mammals or to shrink? I’d wager the former, however, both cases can be seen in humans6Typically, the shrinking scope of care is associated with being hurt or threatened.. Instead of trying to institute controls into AGI systems, the caring AI approach works with the AGI’s own intelligence and agency. Thus we should hypothesize that the more thoroughly caring an AGI system and its incentive ecosystem, the more likely its ongoing growth is to be aligned with care.
Ok, the other fun, crucial idea in the AGI poster is the need to work with indicators of care. Among humans, sans brain-reading (or telepathy), we cannot tell for sure whether someone is acting out of good intent or not and must look to objective signs of intent or beneficial results. Furthermore, it can be difficult to discern what it means to effectively care for another. To this end, I suggest we should ask whether the success of the caring acts is determined collaboratively with the ones being cared for. This should help in ruling out cases where an AGI tries to care for humans in ways that secretly bypass our consent yet attain good scores on various metrics of wellbeing. This seems in line with Stuart Russell’s research on Multi-Principal Assistance Games with Collegial Mechanisms where the humans investing work in achieving their goals helps the assisting AI to better support them (and to deal with potential conflicts of interest, especially attempts to game the system). The definition of collaborative goals I provide requires, imo, some degree of epistemic humility: can one know with 100% certainty that one is not misinterpreting signs of consensual, successful evaluation? Ultimately, one must grant some degree of power over the situation to one’s collaborators!
I’m looking forward to further work in these directions ~ 🤓.
AGI-24 Highlights
Ok, so what about the actual conference? I witnessed a surprising agreement in favor of hybrid neuro-symbolic approaches to AGI. I’d speculate this is because Large Language Models (LLMs) are sufficiently amazing as to be appreciated across the board, yet they also reliably fail at precise, sound reasoning. Thus honest researchers will see that some form of symbolic integration into LLMs, at the very least, may be necessary7It could also be that anyone fully on the neuro-side is too busy working for some semi-secretive company plowing ahead with LLM-centered proto-AGI systems to attend the AGI conference.. I also think that the approaches to improving LLM-based systems increasingly go in the direction of comprehensive architectures with neuro-symbolic characteristics. Retrieval Augmented Generation (RAG) obviously involves some symbolic integration (via embeddings in a vector database) as an approach to allow LLMs to reference material in a database. Chain of thought and scratchpads point to architectures with some sort of ‘working memory’. The use of code evaluation to deal with arithmetical or programmatic problems is fabulous, yet also symbolic of nature8And, yes, it would be highly stupid to rely on LLMs to do arithmetic like “1+1=2” natively.. Should we expect proof-checkers to be integrated into chain-of-thought systems to verify reasoning steps (which will hopefully be more computationally efficient, too)? Probably.
Among those dealing with architectures, I noticed some weak consensus on integrating all the components of an AI agent: transfer learning among components should take place and effective transfer of info should also be realized. Cognitive synergy 😋.
There seemed to be a good degree of focus on caring AGI and on Human-AGI relations.
- I found the MeTTa tutorials fun: the language in its alpha stage is ready to be played with (even as various optimizations to usably speed it up are underway, e.g., MORK and MeTTaLog).
- Michael Bennett’s award-winning paper, “Is Complexity an Illusion?“, makes quite an amusing point that we should actually care about weak constraints instead of simplicity (and that environments such as ours merely nudge the two to largely overlap).
- I found James Oswald’s talk on extending the already incomputable universal intelligence measure to arithmetically uncomputable environments (by conditioning the measure on an oracle). Heck, why not? Our automated theorem provers (ATPs) are learning over semi-decidable domains anyway!
- Joscha Bach’s Cyber-Animist Perspective on AGI was amusing, presenting the view of software as spirits of matter. Running counter to Bennett’s views in “Computational Dualism and Objective Superintelligence” that we should look to what is objectively happening in the hardware, Bach sees the software as what really matters.
- François Chollet’s talk on defining, measuring, and building AGI was also interesting. I liked the idea of seeing intelligence as a fluid process. The ARC challenge seems well made as a localized IQ test for stumping present-day LLMs while being relatively easy for humans.
- Alex Ororbia’s talk on predictive coding provided a wonderful overview of the field of research, explaining how information-propagation bottlenecks in backpropagation can be overcome.
- I found Kristinn Thórisson and Gregorio Talevi’s paper, “A Theory of Foundational Meaning Generation in Autonomous Systems, Natural and Artificial“, to very elegantly present a personally helpful theory of meaning. They propose to view meaning as a process by which an Agent updates its predictions about the world (based on info datum I, situation σ, and knowledge K), its goals G, and its plans Pl. If none of these are (significantly) changed, then I is (essentially) meaningless to the Agent. I find this helpful in analyzing interpersonal situations where we disagree about the meaning to assign to events as well as for analyzing what new mathematical formulas may mean to the theorem prover.
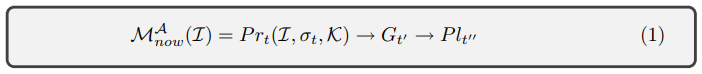
Overall, the quality and atmosphere of the conference felt quite good. Desdemona’s Dream’s performance at the reception was great, too.
AITP-24 Submission Ideas
I chose to do my Ph.D. in AI for mathematics because I wished to work on AGI and see math as sufficiently general (as a problem description language). Diving into the field, I was often flummoxed by how narrow the applied research was: we’re just applying ML to specific formal mathematical benchmarks. Even if, in theory, we can port nearly any problem into a mathematical description, that’s not so readily feasible in practice. Perhaps the SAT (satisfiability) field gets more real-world problems. Moreover, only a minority of researchers seem to be aiming for general mathematical solving AI systems in the big picture, and even among us, there’s a focus on incremental, publishable gains over dealing with what seems obviously necessary to attain full-on AGI ATPs9I must admit that any aspect I deem to be necessary may be obviated by some other AGI techniques that implicitly deal with these aspects, thus bypassing the need to explicitly grapple with them.. Thus I proposed to give a talk on why ATPs are a form of universal AI and how trying to make AGI ATP systems, adopting an AGI architecture perspective, might shed light on difficult research topics and avenues for progress (even incremental). The slides and extended abstract are on the AITP website.
There are a plethora of theoretically appealing universal search procedures and agents built on top of these that should, in theory, be able to solve nearly any well-defined problem or learn to navigate any well-behaved (computational) environment. They generally work by some variant of enumerating and evaluating all possible programs, proofs, or computable environments in a careful manner so as to be guaranteed to find the (optimal*) solution (if one exists). The Gödel Machine even updates its universal intelligence algorithms when it discovers and proves an improvement to them!
In practice, one will need to approximate these algorithms with practical systems. Some OpenCog Hyperon researchers wish to weaken the notion of proof in the Gödel Machine to that of a probabilistic proof (based on the system’s evidence).
Now Automated Theorem Provers are often run in refutation-complete modes where they can derive a contradiction from every unsatisfiable set of formulas. This has recently been extended to a higher-order superposition calculus10See references on Bentkamp’s website.. Constructive proof systems can even provide programs as witneses of the proofs11Mind you, these programs tend to be highly inefficient, wich is par for the course in universal AI!. I believe this qualifies ATPs as universal AIs. Moreover, they’ve probably been optimized for ‘real world’ performance to a far higher degree than most universal AI approaches, which can at least play Pac-Man.
I made a bold claim that cognitive and system architectures are something to be honestly acknowledged, for, practically speaking, certain components will be functionally Isolatable. We should aim to keep all significant system components in the mind’s eye when doing research and, in the case of AGI systems, the systems themselves should also be able to survey and work with all relevant components12I note that humans have not perfected these capacities, yet we seem to have crossed some critical threshhold. Thus perfection is not necessary even as we move in this direction of increasing generality.. I claim that premise selection is a good example of a task that doesn’t need to be isolated from clause selection (choosing the next clause/formula to work with in a proof): it helps a lot to narrow one’s focus of everything not relevant to the matter at hand before trying to solve a puzzle, ya? This modularization should be algorithmically determinable.
Along with many others, I hypothesize that modularized specialization is going to be necessary in practical, resource-limited domains. Most likely (nearly) all effective approximations to universal AIs will involve architectures of more than one component. Present-day proto-AGI systems based on LLMs do. As mentioned above: we have good algorithms for doing many tasks that are far, far more efficient than recoursing to LLMs. LLMs should use them. Furthermore, even if some massive NN in theory ‘does it all’, it could still be possible that the weights form fuzzily distinct components in practice.
I also ambitiously propose that we should include human-in-the-loop components of the overall AI pipelines into the system architectures so that it’s easier to see what needs to be automated. Is it possible to have humans guide training loops in such a way that they directly generate training data for AI models to learn from? Without neural implants, human-in-the-loop components imply low cognitive integration and will become bottlenecks.
Most likely, an AGI-ATP system will live on the level of Interactive Theorem Proving (ITP) systems where the actual math libraries are maintained (and verified), or, possibly, on the level of the humans who work with the ITP systems. The ITP systems often call ATP systems as hammers to discharge sub-goals. I found it fun to try and match different parts of the ITP and ATP ecosystems onto the Laird et al.’s Common Model of Cognition (which was presented at AGI-24).
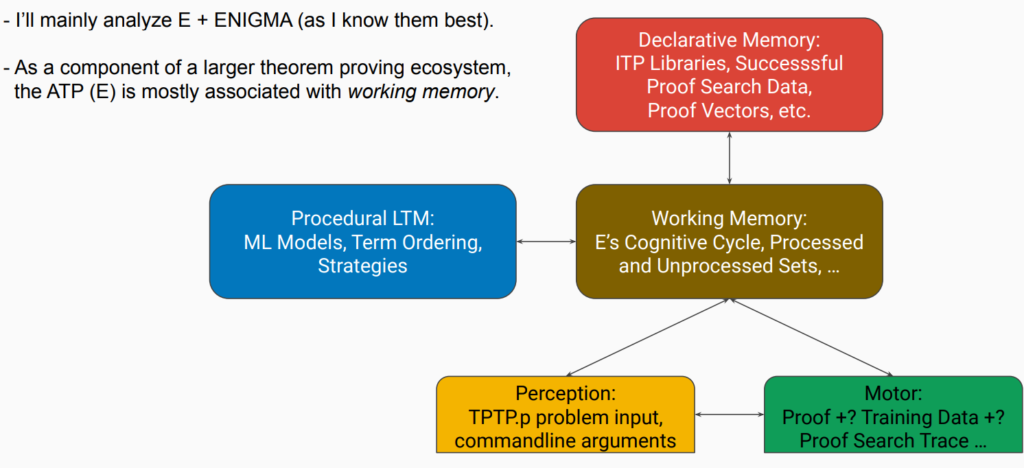

Broadly speaking, I think the ATP world really lacks a sense of incorporating the worldview, context, and autonomy into the AI systems. This ties in with Thórisson and Talevi’s theory of foundation meaning. ATPs don’t have much notion of the meaning of the symbols and theories they are working with in the broader context. Some of my research, such as ProofWatch and EnigmaWatch aimed to integrate more of the semantic mathematical space/context into the proof search. I understand that it’s tricky to do this, moreover, the platonic mathematical realm is a metaphysically contentious notion. Should we further work with geometric models or real-world data that correspond with the math under investigation? Gosh, that’d be such a hassle. [But we probably should 😛.] At a glance, it seems that there is more room for meaning to enter in the realm of ITPs.
I was pleasantly surprised to see work at AITP on “Exploring Metamath Proof Structures13The slides.” by Christoph Wernhard and Zsolt Zombori on lemma discovery via compression, what I spontaneously called inferential compressibility in my presentation. This is in the direction of looking at the full mathematical space and trying to find innately meaningful formulas as lemmas.
I also think it’s important to bestow autonomy upon the AGI-ATP systems: they should be self-organizing and meta-learning, too. Incorporate AI into the process of choosing how to train and tune the parameters of the AI systems.. even more holistically than is already done. Can AI help with identifying choice points in which to insert additional AI models? Can AI suggest, implement, and prove improvements to their proof calculi, term-tree indexes, etc., like the Gödel machine (even if the ‘proofs’ are probabilistic and experimental)?
Furthermore, as an AGI-ATP system becomes increasingly effective, the capacity to autoformalize text and multi-media scenarios into formal problems (and then to translate them back in actionable forms) will allow ATPs to subsume the real world.
Practically speaking, I conjecture that successful incremental integration of AI into/across components of the ATP/ITP ecosystem should lead to increased performance and publishable results in the direction of AGI14However, these incremental components may be slower than going for gold. It’s up for debate..
AITP-24 Highlights
As to the conference, the talks concerning LLMs were very grounded compared with last year. Now they have been used to do quite nifty things such as generating IMO solutions, yet in other domains they’ve hit some bottlenecks. Sean Welleck’s talk on Neural Theorem Proving was interesting: I found especially noteworthy how including the context of a theorem matters a lot for real-world proving (in the context of a Lean proof) whereas it doesn’t matter much for competition problems (the usual ‘benchmarks’).
András Kornai recently released a book, Vector Semantics, so we had a fun panel discussing embedding spaces and symbolic reasoning in AGI-leaning systems. Do we need both? I favor a plurality of modalities. Can probabilistic logics bridge the chasm between formal reasoning and vector semantics?
Nil Geisweiller, Adam Vandervorst, and Anneline Daggelinckx from the OpenCog Hyperon and SingularityNET universe attended, too, which made for some interesting intersections I’d been curious to observe. MeTTa can be seen as a higher-order theorem prover + programming language and Nil is working with backward chainers (for doing inference) in them.
It’s quite fun to see Joao Araujo‘s presentation on a quiet revolution in the domains of simple algebras where Prover9 (a la ProverX) facilitates many novel proofs that humans were not able to (easily) muster before. The proofs can be quite tediously involved in these systems with limited operators to standard arithmetic. I suspect there should be more PR about this work (as it’s not obviously inferior to the DeepMind math results that made the press). Likewise for the years-long project to prove the Weak AIM Conjecture with the help of Prover915Namely that “Every AIM loop is nilpotent of class at most 3.”, which was quietly unveiled at AITP-21 for “all who care” 🙃. This is a rare project where the prover is run for days or weeks and generates proofs of length 100k+ steps, counter to all commonsense of how the search space explodes and it’s hardly worth running for over 30-300 seconds.
A fun pet topic is: how do we learned from failed proof searches? Michael Rawson et al. presented explorations with this “Hindsight Experience Replay” idea, aiming to use a forward reasoning prover (instead of the usual systems that look for a proof by contradiction). The idea is to take some intermediate step K and to say, “if I had been aiming for K, then the following steps would be good.” This seems to run into similar problems as lemma finding: is there any feature of K that sets it apart as a potential end goal? If not, you could hyper-optimize for flopping around in circles. I smell some unsupervised learning here. 🐶
As a mini-conference, AITP is quite nice. Spanning 5 days with breaks for hiking in the afternoon, there’s more room for research discussions and networking than at some conferences. A lot of the presentations are more experimental by design, which further fosters discussions.
With all the psytrance festivals I’ve been attending, I catch myself calling conferences “academic festivals” by mistake. I’d like the evenings of conferences to be more like festivals, honestly: some good, intellectually stimulating psychill might be more conducive to the after dinner chats. Also, it’s fun to connect with people in diverse ways. One night, we played The Crew, a cooperative card game, and another the bartender/DJ played some swing for us to dance some Lindy Hop. I really appreciated the diversity.